

###BeginCaseStudy###
Case Study: 6
Coho Winery
Overview
You are a database developer for a company named Coho Winery. Coho Winery has an
office in London.
Coho Winery has an application that is used to process purchase orders from customers and
retailers in 10 different countries.
The application uses a web front end to process orders from the Internet. The web front end
adds orders to a database named Sales. The Sales database is managed by a server named
Server1.
An empty copy of the Sales database is created on a server named Server2 in the London
office. The database will store sales data for customers in Europe.
A new version of the application is being developed. In the new version, orders will be placed
either by using the existing web front end or by loading an XML file.
Once a week, you receive two files that contain the purchase orders and the order details of
orders fromoffshore facilities.
You run the usp_ImportOders stored procedure and the usp_ImportOrderDetails stored
procedure to copy the offshore facility orders to the Sales database.
The Sales database contains a table named Orders that has more than 20 million rows.
Database Definitions
Database and Tables
The following scripts are used to create the database and its tables:
Stored Procedures
The following are the definitions of the stored procedures used in the database:

Indexes
The following indexes are part of the Sales database: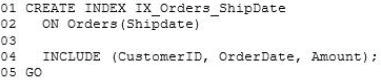
Data Import
The XML files will contain the list of items in each order. Each retailer will have its own
XML schema and will be able to use different types of encoding. Each XML schema will use
a default namespace. The default namespaces are not guaranteed to be unique.
For testing purposes, you receive an XSD file from a customer.
For testing purposes, you also create an XML schema collection named ValidateOrder.
ValidateOrder contains schemas for all of the retailers.
The new version of the application must validate the XML file, parse the data, and store the
parsed data along with the original XML file in the database. The original XML file must be
stored without losing any data.
Reported Issues
Performance Issues
You notice the following for the usp_GetOrdersAndItems stored procedure:
• The stored procedure takes a long time to complete.
• Less than two percent of the rows in the Orders table are retrieved by
usp_GetOrdersAndItems.
• A full table scan runs when the stored procedure executes.
• The amount of disk space used and the amount of time required to insert data are very
high.
You notice that the usp_GetOrdersByProduct stored procedure uses a table scan when the
stored procedure is executed.
Page Split Issues
Updates to the Orders table cause excessive page splits on the IX_Orders_ShipDate index.
Requirements
Site Requirements
Users located in North America must be able to view sales data for customers in North
America and Europe in a single report. The solution must minimize the amount of traffic over
the WAN link between the offices.
Bulk Insert Requirements
The usp_ImportOrderDetails stored procedure takes more than 10 minutes to complete. The
stored procedure runs daily. If the stored procedure fails, you must ensure that the stored
procedure restarts from the last successful set of rows.
Index Monitoring Requirements
The usage of indexes in the Sales database must be monitored continuously. Monitored data
must be maintained if a server restarts. The monitoring solution must minimize the usage of
memory resources and processing resources.
###EndCaseStudy###
You need to implement a solution that addresses the performance issues of the
usp_GetOrdersByProduct stored procedure.
Which statement should you execute?

A.
Option A
B.
Option B
C.
Option C
D.
Option D
Why not create a covering index for this query? That is answer B.
0
0
The query of sp is not very selective, so it should be a benefit to create covering index
to improve the reaad performance.
On the other hand the write performance can get slower.
The requirement is to solve table scan issue:
You notice that the usp_GetOrdersByProduct stored procedure uses a table scan when the
stored procedure is executed.
So maybe index on ProductId is enough to bring the read performance to sufficient level
without slowing down the wright performance significantly.
0
0
Covering index would be the best option, but it needs to cover each colummn to have sense. Any of the answer does it.
0
0
answer is B. if you check the table orderdetails and count all the indexes you’ll understand why 🙂 .. answer C will still return a Scan
0
0
Option B is not covering all the returned columns. If you would use the INCLUDE clause in index creation, be sure to include all referenced columns of the SELECT statement.
So, it’s option C for me!!
0
0
C
There is no clustered index on OrderDetails table.
So, the answer B is not covering index. Column OrderId necessary
0
0
Thats not right, there is a clustered index on the OrderDetails-Table
see row 57 of the tables creations:
constraint pk_orderDetails Primary Key (OrderID, LineItem)
But in the Answers A, B and D the column LineItem is included.
As LineItem is a Part of the PrimaryKey it is not necessary to include this column.
So I agree with Vladimir that Answer C is correct
0
0
Hi,
The correct answer is B.
Cluster index is created at row 57 with columns OrderID and LineItem.
Because LineItem column is second column in cluster index you need to add this column to noncluster index.
So with a clustered index on (OrderID,LineItem) you have all the rows with the same OrderID “grouped” together (in order of LineItem), but the rows with the same OrderID still scattered around the table.
Answer C make sense only to create a smaller index, but sql server will need to use Lookup for other columns.
0
0
**
So with a clustered index on (OrderID,LineItem) you have all the rows with the same OrderID “grouped” together (in order of LineItem), but the rows with the same **LineItem** still scattered around the table.
0
0