

Which is the most efficient process to gather these web servers access logs into your Hadoop cluster for analy
You want to understand more about how users browse your public website. For example, you war
know which pages they visit prior to placing an order. You have a server farm of 200 web server
hosting your website. Which is the most efficient process to gather these web servers access logs
into your Hadoop cluster for analysis?
Which method will have the best runtime performance?
You have a large file of N records (one per line), and want to randomly sample 10% them. You
have two functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1]
random_permotation (M) generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file:
If random_uniform () < 0.1;
Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method will have the best runtime performance?
Which method requires the most RAM?
You have a large file of N records (one per line), and want to randomly sample 10% them. You
have two functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1]
random_permotation (M) generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file:
If random_uniform () < 0.1;
Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method requires the most RAM?
Which method might introduce unexpected correlations?
You have a large file of N records (one per line), and want to randomly sample 10% them. You
have two functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1]
random_permotation (M) generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file:
If random_uniform () < 0.1;
Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method might introduce unexpected correlations?
Which method is least likely to give you exactly 10% of your data?
You have a large file of N records (one per line), and want to randomly sample 10% them. You
have two functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1]
random_permotation (M) generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file:
If random_uniform () < 0.1;
Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method is least likely to give you exactly 10% of your data?
what would we expect the value of the revenue to be in Q1 of 2013?
Assuming the trends shown in this chart continue, what would we expect the value of the revenue to be in Q1 of 2013?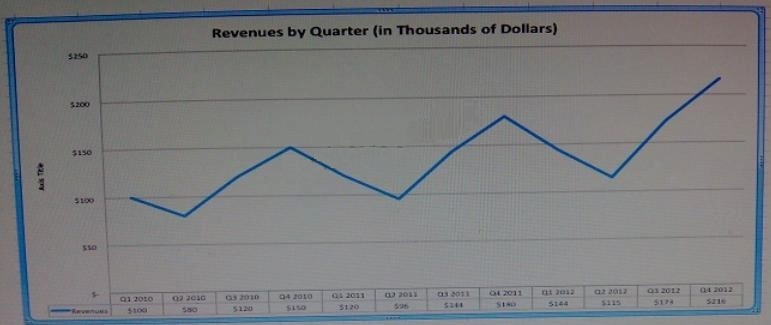
what is the probability that they took cloudera’s introduction to Data Science: Building Recommender Systems
From historical data, you know that 50% of students who take Cloudera’s Introduction to Data
Science: Building Recommenders Systems training course pass this exam, while only 25% of
students who did not take the training course pass this exam. You also know that 50% of this
exam’s candidates also take Cloudera’s Introduction to Data Science: Building Recommendations
Systems training course.
If we know that a person has passed this exam, what is the probability that they took cloudera’s
introduction to Data Science: Building Recommender Systems training course?
What is the probability that any individual exam candidate will pass the data science exam?
From historical data, you know that 50% of students who take Cloudera’s Introduction to Data
Science: Building Recommenders Systems training course pass this exam, while only 25% of
students who did not take the training course pass this exam. You also know that 50% of this
exam’s candidates also take Cloudera’s Introduction to Data Science: Building Recommendations
Systems training course.
What is the probability that any individual exam candidate will pass the data science exam?
which words to use as features in order to contribute to making the correct classification decision?
You want to build a classification model to identify spam comments on a blog. You decide to use
the words in the comment text as inputs to your model. Which criteria should you use when
deciding which words to use as features in order to contribute to making the correct classification
decision?
What are the five numbers that summarize this distribution (the five number summary of sample percentiles)?
Given the following sample of numbers from a distribution:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89
What are the five numbers that summarize this distribution (the five number summary of sample
percentiles)?