

Which regularization technique should you use to prune features that aren’t contributing to the model?
You are working with a logistic regression model to predict the probability that a user will click on
an ad. Your model has hundreds of features, and you’re not sure if all of those features are
helping your prediction. Which regularization technique should you use to prune features that
aren’t contributing to the model?
determine the best technique for predicting whether or not a given individual is susceptible to developing aut
Certain individuals are more susceptible to autism if they have particular combinations of genes
expressed in their DNA. Given a sample of DNA from persons who have autism and a sample of
DNA from persons who do not have autism, determine the best technique for predicting whether
or not a given individual is susceptible to developing autism?
Which point in the figure is the median?
Refer to the exhibit.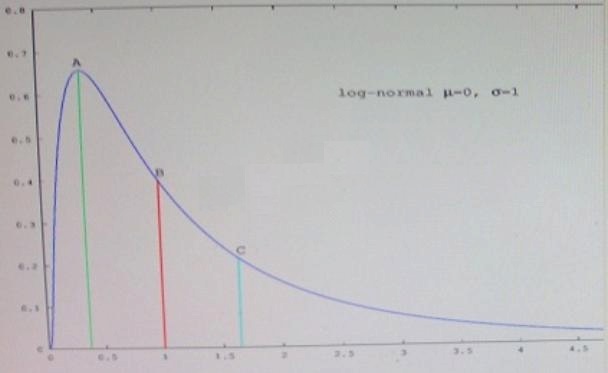
Which point in the figure is the median?
Which point in the figure is the mode?
Refer to the exhibit.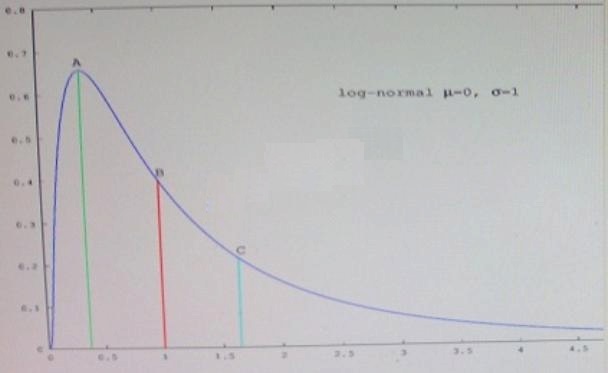
Which point in the figure is the mode?
Which point in the figure is the mean?
Refer to the exhibit.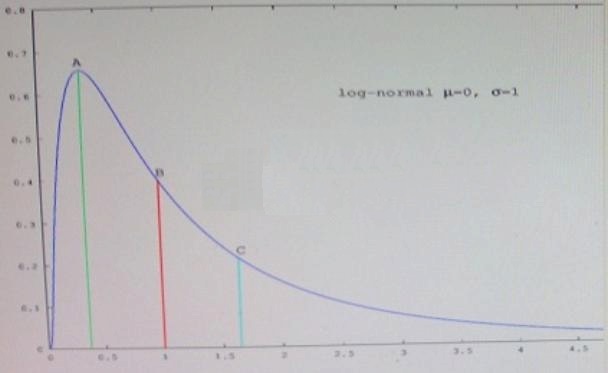
Which point in the figure is the mean?
what two conditions does stochastic gradient descent outperform 2nd-order optimization techniques such as iter
Under what two conditions does stochastic gradient descent outperform 2nd-order optimization
techniques such as iteratively reweighted least squares?
What is the result of the following command (the database username is foo and password is bar)?
What is the result of the following command (the database username is foo and password is bar)?
$ sqoop list-tables – – connect jdbc : mysql : / / localhost/databasename – – table – – username foo –
– password bar
What is the most common reason for a k-means clustering algorithm to returns a sub-optimal clustering of its i
What is the most common reason for a k-means clustering algorithm to returns a sub-optimal
clustering of its input?
What is the most reliable way to fix this problem?
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid
leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows: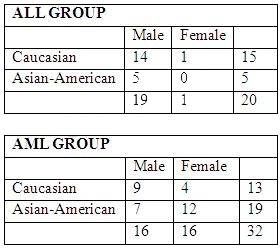
Each individual has an expression value for each of 10000 different genes. The expression value
for each gene is a continuous value between -1 and 1.
You’ve built your model for discriminating between AML and ALL patients and you find that it
works quite well on your current data. One month later, a collaboration tells you she has fresh
data from 100 new AML/ALL patients. You run the samples through your model, and turns out
your model has very poor predictive accuracy on the new samples; specifically, your model
predicts that all males have ALL. What is the most reliable way to fix this problem?
What type of data science problem is this?
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid
leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows: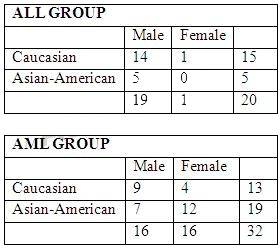
Each individual has an expression value for each of 10000 different genes. The expression value
for each gene is a continuous value between -1 and 1.
You want to use the data from the 52 patients in the scenario to improve the ability of doctors
being able to distinguish between ALL and AML. What type of data science problem is this?