

Note: This question is part of a series of questions that present the same scenario. Each question in this series
contains a unique solution. Determine whether the solution meets the stated goals.
The Account table was created using the following Transact-SQL statement:
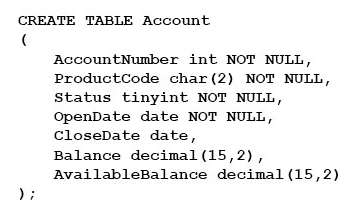
There are more than 1 billion records in the Account table. The Account Number column uniquely identifies
each account. The ProductCode column has 100 different values. The values are evenly distributed in the
table. Table statistics are refreshed and up to date.
You frequently run the following Transact-SQL SELECT statements:

You must avoid table scans when you run the queries.
You need to create one or more indexes for the table.
Solution: You run the following Transact-SQL statement:
CREATE CLUSTERED INDEX PK_Account ON Account(ProductCode);
Does the solution meet the goal?

A.
Yes
B.
No
Explanation:
We need an index on the productCode column as well.
https://msdn.microsoft.com/en-us/library/ms190457.aspx
I think it’s incorrect answer. Once the clustered index is created, table scans will not occur.
3
12
I think answer is correct. First select read 99% of data, so the only possiblity to avoid table scan is to crate non clustered index covering a query. Then we will have nonclustered index scan. Clustered index scan is still table scan.
18
1
I am not too sure i agree here. you will not get an clustered index scan if your create an index covering the productcode column and run the queries.
1
1
There is a misspelling. In the second query should be ProductCode instead of Production (such column doesn’t exist in the table).
I agree with jml’s comment above. You need to read 99% of data, so you will have scan anyway.
2
1