

Note: This question is part of a series of questions that use the same answer choices. An answer choice may
be correct for more than one question on the series. Each question is independent of the other questions in this
series. Information and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the
following table:
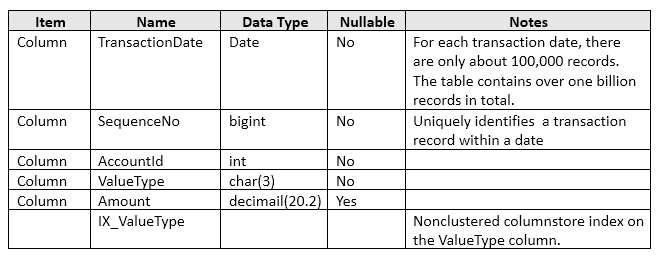
Users report that the following query takes a long time to complete.

You need to create an index that:
– improves the query performance
– does not impact the existing index
– minimizes storage size of the table (inclusive of index pages).
What should you do?

A.
Create aclustered index on the table.
B.
Create a nonclustered index on the table.
C.
Create a nonclustered filtered index on the table.
D.
Create a clustered columnstore index on the table.
E.
Create a nonclustered columnstore index on the table.
F.
Create a hashindex on the table.
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a welldefined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered
index can improve query performance, reduce index maintenance costs, and reduce index storage costs
compared with full-table indexes.
I think the answer should be “B, nonclustered index on the table”, there is no need to filter.
4
4
Never mind, we need to use filtered non clustered index because of the number of record in the table is one billion.
1
2
we need to use filtered non clustered index because of the number of record in the table is one billion and there is a WHERE clause.
0
2
I think nonclustered columnstore index because we have a group by so we need to scan all table
for aggregation, ideal index is columnstore index
6
5
I think the same. Columnstore index is very fast when we have aggregations. Also it has a small size.
But I’m not 100% sure about this answer.
2
1
there is already a columnstore index and the question says does not impact the existing index so it can’t be columstore
6
1
there is already a non clustered index, so we can add a clustered index (row or colum store) or many non clustered index we want. in this case my opinion is “Create a nonclustered columnstore index on the table” on the TransactionDate column. (one billion of rows is a good candidate to a columnstore index)
1
4
The need to create an index that: improve the query performance and minimizes storage, are possibly the most important reasons to select, create a nonclustered filtered index on the table(B). Because, filtered indexes offer great benefits in terms of query execution performance and index storage savings. Because traditional nonclustered indexes are so necessary, but can rack up high maintenance and storage costs, the filtered index optimization should be considered wherever possible.
0
3
and what should the filter be ?
each day the query would search a different date.
i trust the answer is non cluster columnstore on the TransactionDate(that is the only column queried) : Columnstore indexes benefit of 10X (more or less) compress ratio
1
0
I think correct answer is F. Detail information for bucket count supplied, Excellent when the predicate in the WHERE clause specifies an exact value for each column.
0
8
Hash indexes are only for memory optimized tables. There is no memory-optimized filegroup. Answer should be C imo.
4
0
It’s impossible to create two columstores index on the same table.
9
2
Multiple columnstore indexes are not supported so D and E are out.
It’s not memory optimised so F is out.
Value in where clause is not exact so can’t create filtered index based on where clause; C is out.
Between A and B, I’d go with A because of requirement “minimizes storage size of the table (inclusive of index pages)” since clustered index will reorganize existing data without increasing storage size.
20
0
A
2
0