

Which tool should you use?
You maintain a SQL Server Integration Services (SSIS) package. The package was
developed by using SQL Server 2008 Business Intelligence Development Studio (BIDS).
The package includes custom scripts that must be upgraded.
You need to upgrade the package to SQL Server 2012.
Which tool should you use?
You need to reduce the report processing time and minimize the growth of the database
You are reviewing the design of an existing fact table named factSales, which is loaded from
a SQL Azure database by a SQL Server Integration Services (SSIS) package each day. The
fact table has approximately 1 billion rows and is dimensioned by product, sales date, and
sales time of day.
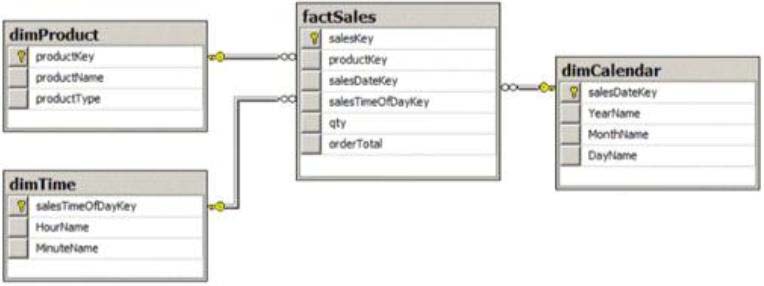
The database administrator is concerned about the growth of the database. Users report
poor reporting performance against this database. Reporting requirements have recently
changed and the only remaining report that uses this fact table reports sales by product
name, sale month, and sale year. No other reports will be created against this table.
You need to reduce the report processing time and minimize the growth of the database.
What should you do?
Which three stored procedures should you execute in sequence?
DRAG DROP
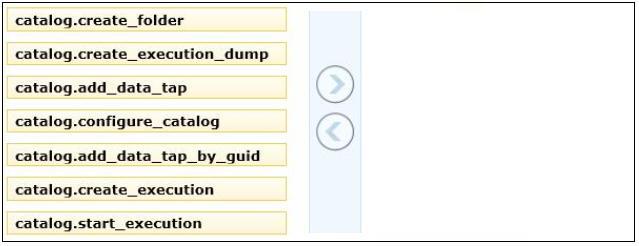
A new SQL Server Integration Services (SSIS) project is deployed to the SSIS catalog.
To troubleshoot some data issues, you must output the data streaming through several data
flows into text files for further analysis. You have the list of data flow package paths and
identification strings of the various task components that must be analyzed.
You need to create these output files with the least amount of administrative and
development effort.
Which three stored procedures should you execute in sequence? (To answer, move the
appropriate actions from the list of actions to the answer area and arrange them in the
correct order.)
Which three steps should you perform in sequence?
DRAG DROP
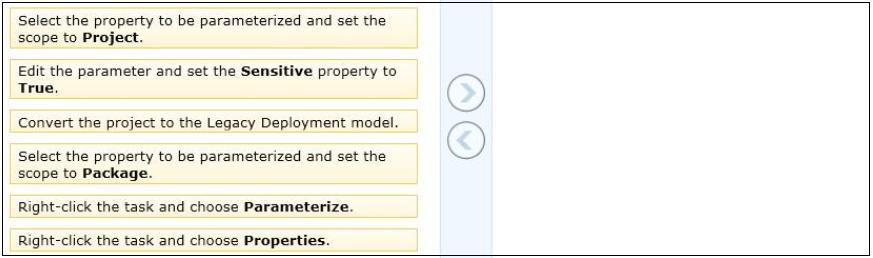
You are editing a SQL Server Integration Services (SSIS) package that contains a task with
a sensitive property.
You need to create a project parameter and configure it so that its value is encrypted when it
is deployed to the SSIS catalog.
Which three steps should you perform in sequence? (To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.)
You need to design a solution that can join a single time dimension to both fact tables
You are designing a data warehouse with two fact tables. The first table contains sales per
month and the second table contains orders per day.
Referential integrity must be enforced declaratively.
You need to design a solution that can join a single time dimension to both fact tables.
What should you do?
You need to design the software title dimension
You are designing a data warehouse for a software distribution business that stores sales by
software title. It stores sales targets by software category. Software titles are classified into
subcategories and categories. Each software title is included in only a single software
subcategory, and each subcategory is included in only a single category. The data
warehouse will be a data source for an Analysis Services cube.
The data warehouse contains two fact tables:
factSales, used to record daily sales by software title
factTarget, used to record the monthly sales targets by software category
Reports must be developed against the warehouse that reports sales by software title,
category and subcategory, and sales targets.
You need to design the software title dimension. The solution should use as few tables as
possible while supporting all the requirements.
What should you do?
You need to design a table structure to ensure that certain users can see sales data for only certain district
You are designing a data warehouse hosted on SQL Azure. The data warehouse currently
includes the dimUser and dimDistrict dimension tables and the factSales fact table. The
dimUser table contains records for each user permitted to run reports against the
warehouse; and the dimDistrict table contains information about sales districts.
The system is accessed by users from certain districts, as well as by area supervisors and
users from the corporate headquarters.
You need to design a table structure to ensure that certain users can see sales data for only
certain districts. Some users must be permitted to see sales data from multiple districts.
What should you do?
You need to redesign the dimension to enable the full historical reporting of changes to multiple customer att
You are reviewing the design of a customer dimension table in an existing data warehouse
hosted on SQL Azure.
The current dimension design does not allow the retention of historical changes to customer
attributes such as Postcode.
You need to redesign the dimension to enable the full historical reporting of changes to
multiple customer attributes including Postcode.
What should you do?
You need to ensure that the indexing strategy meets the requirements
You are implementing the indexing strategy for a fact table in a data warehouse. The fact
table is named Quotes. The table has no indexes and consists of seven columns:
• [ID]
• [QuoteDate]
• [Open]
• [Close]
• [High]
• [Low]
• [Volume]
Each of the following queries must be able to use a columnstore index:
• SELECT AVG ([Close]) AS [AverageClose] FROM Quotes WHERE [QuoteDate]
BETWEEN ‘20100101’ AND ‘20101231’.
• SELECT AVG([High] – [Low]) AS [AverageRange] FROM Quotes WHERE
[QuoteDate] BETWEEN ‘20100101’ AND ‘20101231’.
• SELECT SUM([Volume]) AS [SumVolume] FROM Quotes WHERE [QuoteDate]
BETWEEN ‘20100101’ AND ‘20101231’.
You need to ensure that the indexing strategy meets the requirements. The strategy must
also minimize the number and size of the indexes.
What should you do?
You need to design a consolidated dimensional structure that will be easy to maintain while ensuring that all
You are designing an enterprise star schema that will consolidate data from three
independent data marts. One of the data marts is hosted on SQL Azure.
Most of the dimensions have the same structure and content. However, the geography
dimension is slightly different in each data mart.
You need to design a consolidated dimensional structure that will be easy to maintain while
ensuring that all dimensional data from the three original solutions is represented.
What should you do?