

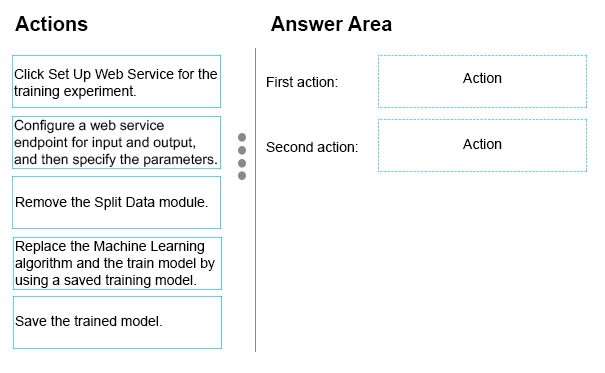
Which two actions should you perform to convert the Mac…
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the
scenario is repeated in each question. Each question presents a different goal and answer choices, but the text
of the scenario is exactly the same in each question in this series.
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure
Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your
organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services.
The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will
predict probabilities in an Apache Hadoop ecosystem.
You finish training the model and are ready to publish a predictive web service that will provide the users with
the ability to specify the data source and the save location of the results. The model includes a Split Data
module.
Which two actions should you perform to convert the Machine Learning experiment to a predictive web service?
To answer, drag the appropriate actions to the correct targets. Each action may be used once, more than once,
or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.Select and Place:
Which module should you add after the web service input…
Note: This question is part of a series of questions that use the same scenario. For your convenience, the
scenario is repeated in each question. Each question presents a different goal and answer choices, but the text
of the scenario is exactly the same in each question in this series.
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure
Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your
organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services.
The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will
predict probabilities in an Apache Hadoop ecosystem.
You need to alter the list of columns that will be used for predicting fraud for an input web service endpoint. The
columns from the original data source must be retained while running the Machine Learning experiment.
Which module should you add after the web service input module and before the prediction module?
Which three actions should you perform?
Note: This question is part of a series of questions that use the same scenario. For your convenience, the
scenario is repeated in each question. Each question presents a different goal and answer choices, but the textof the scenario is exactly the same in each question in this series.
You plan to create a predictive analytics solution for credit risk assessment and fraud prediction in Azure
Machine Learning. The Machine Learning workspace for the solution will be shared with other users in your
organization. You will add assets to projects and conduct experiments in the workspace.
The experiments will be used for training models that will be published to provide scoring from web services.
The experiment for fraud prediction will use Machine Learning modules and APIs to train the models and will
predict probabilities in an Apache Hadoop ecosystem.
You plan to configure the resources for part of a workflow that will be used to preprocess data from files stored
in Azure Blob storage. You plan to use Python to preprocess and store the data in Hadoop.
You need to get the data into Hadoop as quickly as possible.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Which Machine Learning library should you use?
You are performing exploratory analysis of files that are encoded in a complex proprietary format. The format
requires disk intensive access to several dependent files in HDFS.
You need to build an Azure Machine Learning model by using a canopy clustering algorithm. You must ensure
that changes to proprietary file formats can be maintained by using the least amount of effort.
Which Machine Learning library should you use?
Which statement should you use?
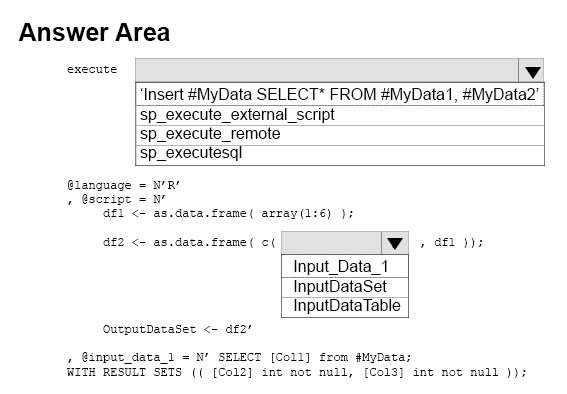
HOTSPOT
You need to use R code in a Transact-SQL statement to merge the repeating values 1 through 6 with Col1 in a
table.
Which statement should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Which IDE should you use?
You plan to use the Data Science Virtual Machine for development, but you are unfamiliar with R scripts.
You need to generate R code for an experiment.
Which IDE should you use?
Which type of Azure HDInsight cluster should you use to…
You are analyzing taxi trips in New York City. You leverage the Azure Data Factory to create data pipelines and
to orchestrate data movement.
You plan to develop a predictive model for 170 million rows (37 GB) of raw data in Apache Hive by using
Microsoft R Server to identify which factors contribute to the passenger tipping behavior.
All of the platforms that are used for the analysis are the same. Each worker node has eight processor cores
and 26 GB of memory.
Which type of Azure HDInsight cluster should you use to produce results as quickly as possible?
Which SGD algorithm should you use?
You are building an Azure Machine Learning workflow by using Azure Machine Learning Studio.You create an Azure notebook that supports the Microsoft Cognitive Toolkit.
You need to ensure that the stochastic gradient descent (SGD) configuration maximizes the samples per
second and supports parallel modeling that is managed by a parameter server.
Which SGD algorithm should you use?
You need to modify the solution
From the Cortana Intelligence Gallery, you deploy a solution.
You need to modify the solution.
What should you use?
Which module should you use?
Note: This question is part of a series of questions that use the same or similar answer choices. An answer
choice may be correct for more than one question in the series. Each question is independent of the other
questions in this series. Information and details provided in a question apply only to that question.
You need to use only one percent of an Apache Hive data table by conducting random sampling by groups.
Which module should you use?