Which migration option creates the least amount of downtime for the clustered application?
An administrator is migrating from PowerHA 5.4.1 to PowerHA 6.1. Which migration option creates
the least amount of downtime for the clustered application?
What must the company implement in order to use IP address takeover via IP aliasing?
A company plans to deploy a 2-node PowerHA cluster using IP address takeover via IP aliasing.
The HA nodes are POWER7 LPARs supported by VIO Servers. The nodes are located on
different sites. Each site has its own network.
What must the company implement in order to use IP address takeover via IP aliasing?
where can the keystore be located?
With encrypted filesystem configuration in a cluster, where can the keystore be located?
What is the correct way to accomplish this?
As a part of PowerHA customization an administrator wants to change the location of hacmp.out
log file. What is the correct way to accomplish this?
How can the administrator test the rootvg system event to ensure the change behaves as expected?
An administrator has installed and configured AIX and PowerHA 7 on multipath vSCSI disks.
There are two VIO Servers, and both are accessing the same SAN storage system. The
administrator has modified setting for the rootvg system event in the cluster. The cluster is
synchronized and stable.
How can the administrator test the rootvg system event to ensure the change behaves as
expected?
Which utility can be used while a rolling migration is in progress?
Which utility can be used while a rolling migration is in progress?
What happens when an administrator adds a resource group to a cluster using DARE?
What happens when an administrator adds a resource group to a cluster using DARE?
How can the administrator ensure that the resource groups failover when the service address is not contactable
A cluster consists of 2 base boot addresses per node. Each boot address can contact the other
node in the cluster but is not externally routable. There is one service IP address in cluster which
is externally routable.
The external network experienced a problem where the service IP could not be contacted by the
users, but the base boot addresses were still able to send heartbeat packets between the cluster
nodes. The resource groups did not failover to the other node where there was no network
problem.
How can the administrator ensure that the resource groups failover when the service address is
not contactable on a node?
what action will ensure proper detection of an adapter or network failure?
When designing a PowerHA 6 cluster that will use virtual networks, what action will ensure proper
detection of an adapter or network failure?
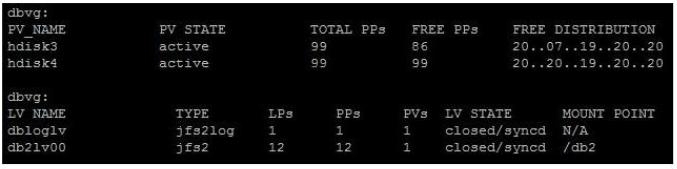
what must be done for PowerHA to perform a successful forced varyon of volume groups?
Based on the output below, what must be done for PowerHA to perform a successful forced varyon of volume groups?