

Which vSphere feature is the likely source of this error?
An administrator receives the following error message:
Unmanaged I/O workload detected on shared datastore.
Which vSphere feature is the likely source of this error?
What condition could cause this behavior?
A vSphere administrator is configuring a fully automated DRS cluster and determines that DRS is
not balancing virtual machine workloads.
What condition could cause this behavior?
What condition could result in this behavior?
An organization has a HA/DRS cluster containing a mixture of ESXi 4.1 and 5.5 hosts in the
cluster. An ESXi 5.5 host has failed and HA attempted but failed to restart the virtual machines on
another host. HA admission control is disabled.
What condition could result in this behavior?
Which condition will cause a HA/DRS cluster to display a yellow health indicator?
Which condition will cause a HA/DRS cluster to display a yellow health indicator?
What is the likely reason for the indication?
A vSphere administrator finds a HA/DRS cluster status has turned RED indicating a degraded
state.
What is the likely reason for the indication?
What is indicated by the performance chart shown?
— Exhibit —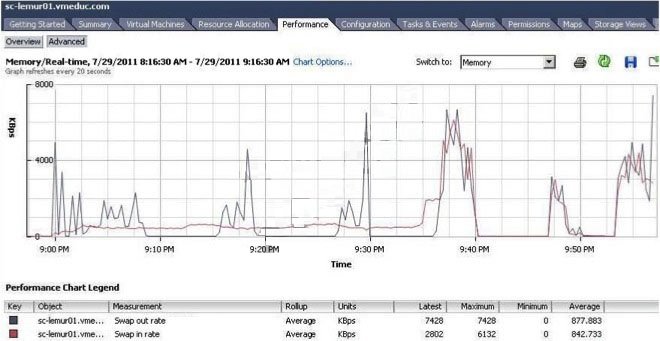
— Exhibit —
What is indicated by the performance chart shown?
What must the administrator do to collect this information?
An administrator needs to use performance information from Windows virtual machines to better
understand their effect on the vSphere 5.x hosts on which they run.
What must the administrator do to collect this information?
Which procedure will satisfy the requirement with the least amount of administrator intervention?
A vSphere administrator receives a request to capture the state of a virtual machine six times a
day.
Which procedure will satisfy the requirement with the least amount of administrator intervention?
What action should an administrator take to store ESXi 5.x host system logs centrally?
What action should an administrator take to store ESXi 5.x host system logs centrally?
Where should the administrator set the alarm to meet the requirement?
An administrator needs to configure an alarm that notifies administrators if an application is
impacted by overcommitment of memory resources. The environment consists of 100 virtual
machines running on 5 ESXi hosts that are configured in a fully automated HA/DRS cluster. The
cluster is configured with a parent resource pool and Production and Development child pools.
Where should the administrator set the alarm to meet the requirement?