You need to minimize how long it takes to find the reco…
You have a fact table named PowerUsage that has 10 billion rows. PowerUsage contains data about customerpower usage during the last 12 months. The usage data is collected every minute. PowerUsage contains the
columns configured as shown in the following table.
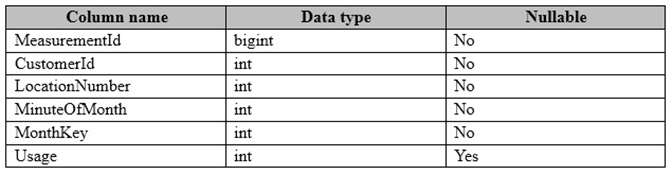
LocationNumber has a default value of 1. The MinuteOfMonth column contains the relative minute within each
month. The value resets at the beginning of each month.
A sample of the fact table data is shown in the following table.
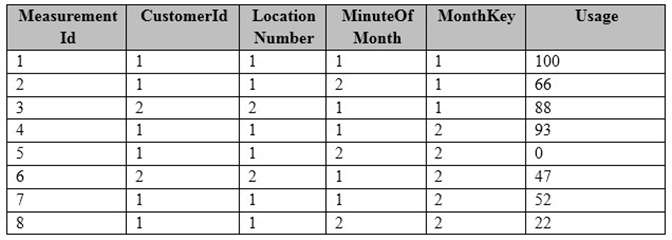
There is a related table named Customer that joins to the PowerUsage table on the CustomerId column. Sixty
percent of the rows in PowerUsage are associated to less than 10 percent of the rows in Customer. Most
queries do not require the use of the Customer table. Many queries select on a specific month.
You need to minimize how long it takes to find the records for a specific month.
What should you do?
Which value should set for the DWUs?
You have a Microsoft Azure SQL data warehouse.
You need to configure Data Warehouse Units (DWUs) to ensure that you have six compute nodes. The
solution must minimize costs.
Which value should set for the DWUs?
Which statement should you execute?
You have an extract, transformation, and load (ETL) process for a Microsoft Azure SQL data warehouse.
You run the following statements to create the logon and user for an account that will run the nightly data load
for the data warehouse.
CREATE LOGIN LoaderLogin WITH PASSWORD = ‘mypassword’;
CREATE USER LoaderUser for LOGIN LoaderLogin;
You connect to the data warehouse.
You need to ensure that the user can access the highest resource class.
Which statement should you execute?
You need to export 10 TB of data from a data warehouse …
You have a Microsoft Azure SQL data warehouse that has 10 compute nodes.
You need to export 10 TB of data from a data warehouse table to several new flat files in Azure Blob storage.
The solution must maximize the use of the available compute nodes.
What should you do?
Which two statements should you execute?
You have a Microsoft Azure SQL data warehouse. The following statements are used to define file formats in
the data warehouse.
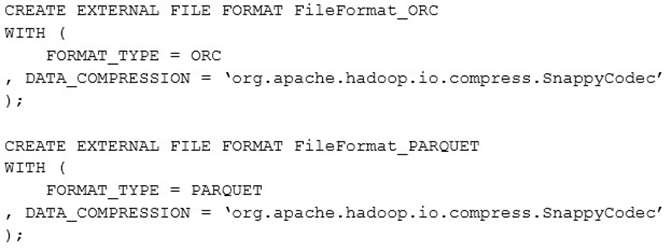
You have an external PolyBase table named file_factPowerMeasurement that uses the FileFormat_ORC file
format.
You need to change file_ factPowerMeasurement to use the FileFormat_PARQUET file format.
Which two statements should you execute? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
You need to reduce the execution time of queries that g…
You have a Microsoft Azure SQL data warehouse that has a fact table named FactOrder. FactOrder contains
three columns named CustomerId, OrderId, and OrderDateKey. FactOrder is hash distributed on CustomerId.
OrderId is the unique identifier for FactOrder. FactOrder contains 3 million rows.
Orders are distributed evenly among different customers from a table named dimCustomers that contains 2
million rows.
You often run queries that join FactOrder and dimCustomers by selecting and grouping by the OrderDateKey
column.
You add 7 million rows to FactOrder. Most of the new records have a more recent OrderDateKey value than the
previous records.
You need to reduce the execution time of queries that group on OrderDateKey and that join dimCustomers and
FactOrder.
What should you do?
Which role should you assign to the user?
You have a Microsoft Azure Data Lake Analytics service.
You need to provide a user with the ability to monitor Data Lake Analytics jobs. The solution must minimize the
number of permissions assigned to the user.
Which role should you assign to the user?
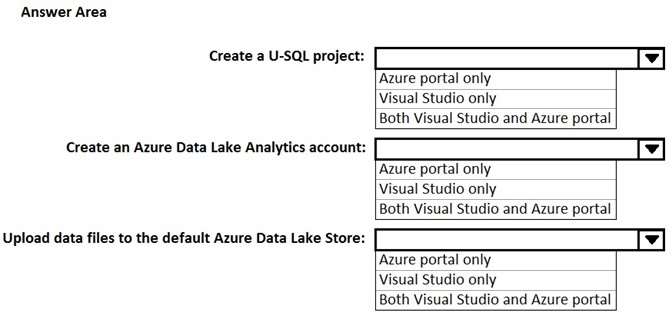
What should you identify for each task?
HOTSPOT
You use Microsoft Visual Studio to develop custom solutions for customers who use Microsoft Azure Data Lake
Analytics.
You install the Data Lake Tools for Visual Studio.
You need to identify which tasks can be performed from Visual Studio and which tasks can be performed from
the Azure portal.
What should you identify for each task? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Which Python module should you install?
You have a Microsoft Azure Data Lake Analytics service and an Azure Data Lake Store.
You need to use Python to submit a U-SQL job.
Which Python module should you install?
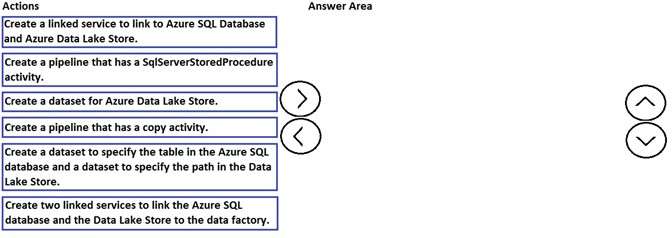
Which three actions should you perform in sequence?
DRAG DROP
You need to copy data from Microsoft Azure SQL Database to Azure Data Lake Store by using Azure Data
Factory.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of
actions to the answer area and arrange them in the correct order.
Select and Place: