

Which technology should you implement?
Note: This question is part of a series of questions that use the same scenario. For your convenience, the
scenario is repeated in each question. Each question presents a different goal and answer choices, but the text
of the scenario is exactly the same in each question in this series.
You are planning a big data infrastructure by using an Apache Spark cluster in Azure HDInsight. The cluster
has 24 processor cores and 512 GB of memory.
The architecture of the infrastructure is shown in the exhibit. (Click the Exhibit button.)
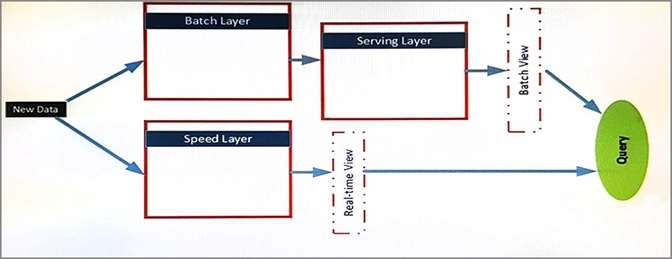
The architecture will be used by the following users:
Support analysts who run applications that will use REST to submit Spark jobs.
Business analysts who use JDBC and ODBC client applications from a real-time view. The business
analysts run monitoring queries to access aggregate results for 15 minutes. The results will be referenced
by subsequent queries.
Data analysts who publish notebooks drawn from batch layer, serving layer, and speed layer queries. All of
the notebooks must support native interpreters for data sources that are batch processed. The serving layer
queries are written in Apache Hive and must support multiple sessions. Unique GUIDs are used across the
data sources, which allow the data analysts to use Spark SQL.
The data sources in the batch layer share a common storage container. The following data sources are used:
Hive for sales data
Apache HBase for operations data
HBase for logistics data by using a single region server
You need to ensure that the analysts can query the logistics data by using JDBC APIs and SQL APIs.
Which technology should you implement?
You need to maximize the amount of concurrent tasks for…
Note: This question is part of a series of questions that use the same or similar answer choices. An answer
choice may be correct for more than one question in the series. Each question is independent of the other
questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You plan to import 300 TB of data.
You plan to use one job that has many concurrent tasks to import the data in memory.
You need to maximize the amount of concurrent tasks for the job.
What should you do?
You need to ensure that you can access the data by usin…
Note: This question is part of a series of questions that use the same or similar answer choices. An answer
choice may be correct for more than one question in the series. Each question is independent of the other
questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You have data stored in Azure.
You need to ensure that you can access the data by using Azure Active Directory (Azure AD) identities.
What should you do?
You need to minimize the execution time of the queries …
Note: This question is part of a series of questions that use the same or similar answer choices. An answer
choice may be correct for more than one question in the series. Each question is independent of the other
questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You have a table that contains sales data.
You plan to implement a query that will return the number of orders by zip code.
You need to minimize the execution time of the queries and to maximize the compression level of the resulting
data.
What should you do?
Which credentials should you use?
DRAG DROP
You have a domain-joined Apache Hadoop cluster in Azure HDInsight named hdicluster. The Linux account for
hdicluster is named Inxuser.
Your Active Directory account is named user1@fabrikam.com.
You need to run Hadoop commands from an SSH session.
Which credentials should you use? To answer, drag the appropriate credentials to the correct commands. Each
credential may be used once, more than once, or not at all. You may need to drag the split bar between panes
or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Which type of HDInsight cluster should you create for e…
DRAG DROP
You are evaluating the use of Azure HDInsight clusters for various workloads.
Which type of HDInsight cluster should you create for each workload? To answer, drag the appropriate cluster
types to the correct workloads. Each cluster type may be used once, more than once, or not at all. You may
need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

You need to integrate Apache Sqoop data and to chain co…
Note: This question is part of a series of questions that use the same or similar answer choices. An answer
choice may be correct for more than one question in the series. Each question is independent of the other
questions in this series. Information and details provided in a question apply only to that question.
You are implementing a batch processing solution by using Azure HDInsight.
You need to integrate Apache Sqoop data and to chain complex jobs. The data and the jobs will implement
MapReduce.
What should you do?
Which role should you assign for each task?
DRAG DROP
You have a domain-joined Azure HDInsight cluster.
You plan to assign permissions to several support staff.
You need to assign roles to the staff so that they can perform specific tasks. The solution must use the principle
of least privilege.
Which role should you assign for each task? To answer, drag the appropriate roles to the correct targets. Each
role may be used once, more than once, or not at all. You may need to drag the split bar between panes or
scroll to view content.
Select and Place:

Which tool should you use?
You have an Apache Hadoop cluster in Azure HDInsight that has a head node and three data nodes. You have
a MapReduce job.
You receive a notification that a data node failed.
You need to identify which component cause the failure.
Which tool should you use?
Which type of file format should you use?
You have an Azure HDInsight cluster.
You need to store data in a file format that maximizes compression and increases read performance.
Which type of file format should you use?