

Which of the following must the administrator do before adding the tape drives to the cluster resource group?
An administrator wants to assign a tape drive to a resource group for ease of management and
control.
The tape drive is already attached to two cluster nodes. Node1 and Node2.
On Node1, the tape drive has a logical device name of rmt1. Node1 also has a tape drive, rmt0,
that is not controlled by the cluster.
On Node2 the tape drive has a logical device name of rmt0.
Which of the following must the administrator do before adding the tape drives to the cluster
resource group?
Which group of actions will create a shared volume group that complies with company storage policy?
Company policy requires logical volumes to be mirrored across separate disks and controllers for
resilience. An administrator needs to create a 2-node cluster with the existing partitions, LPAR1
and LPAR2.The cluster will host an application with data on a shared volume group.
LPAR1 and LPAR2 are currently hosted on a single Power 770. Each partition is assigned two
integrated SAS controllers, each of which has internal hard disk drives (HDDs) that are currently
used for rootvg.
Which group of actions will create a shared volume group that complies with company storage
policy?
How can the cluster configuration revert to the previous configuration without affecting the online resource g
An administrator unintentionally changed the name of an online resource group on one node of a
2-node cluster. The cluster has not been synchronized since the change was made.
How can the cluster configuration revert to the previous configuration without affecting the online
resource group?
what is recommended to ensure I/O disk-write buffers are flushed and to reduce chance of deadman switch timeou
In a PowerHA 6 environment, what is recommended to ensure I/O disk-write buffers are flushed
and to reduce chance of deadman switch timeouts?
what is the most amount of time it will take for a failover event to begin?
A 2-node cluster configuration has an application server named appl. The appl server has custom
application monitors named appmon_a and appmon_b.
The setting of appmon_a and appmon_b follows:
appmon_a: monitoring process=A, monitor interval=20, stabilization interval=60, restart count=1
appmon_b: monitoring process=B, monitor interval=10, stabilization interval=60, restart count=0 If
process B fails 30 seconds after process A fails and successfully restarts, what is the most amount
of time it will take for a failover event to begin?
Which application dependency can cause problems if the application is installed on a shared disk?
Which application dependency can cause problems if the application is installed on a shared disk?
a single-adapter configuration must recognize a network_down event if a node loses access to….
9.12.4.11 9.12.4.13
!REQD!ALL 100.12.7.9
!REQD!ALL 100.12.7.10
Given the netmon.cf file above, a single-adapter configuration must recognize a network_down
event if a node loses access to_______________:
Which pre-defined event would be best to specify the custom event?
A resource group is configured with a startup policy of “Online on First Available Node” and a
service IP address which uses IPAT via aliasing. An administrator needs a custom event to run
only during a failover.
Which pre-defined event would be best to specify the custom event?
Which task, or tasks, should be completed next?
A customer has completed installing PowerHA 7 filesets. Which task, or tasks, should be
completed next?
Why did Node2 halt?
An active, active (mutual takeover) 2-node PowerHA cluster is currently up and stable. Both nodes
are located in separate buildings, one kilometer apart. Node2 in SiteB suddenly powers off. On
reboot of the failed node, the cluster administrator checks the error log and discovers the node
had been halted. The network team confirms there was a temporary loss of the IP network between sites.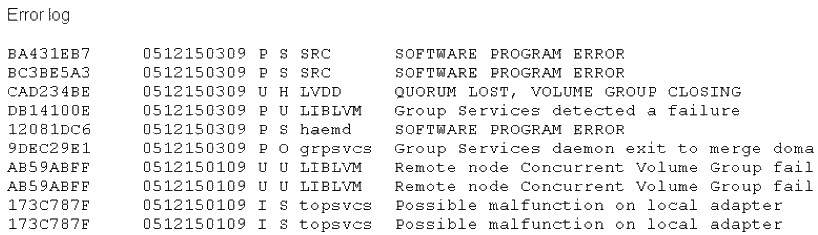
Why did Node2 halt?