

Which feature of HBase ensures predictable disk head seek performance within a RegionServer?
Which feature of HBase ensures predictable disk head seek performance within a RegionServer?
Which of these should you choose for a row key to maximize your write throughput?
You have 40 Web servers producing timeseries data from Web traffic logs. You want to attain high
write throughput for storing this data in an HBase table. Which of these should you choose for a
row key to maximize your write throughput?
which of the following?
Your client application needs to scan s region for the row key value 104.
Given a store that contains the following list of Row Key values:
100, 101, 102, 103, 104, 105, 106, 107
A bloom filter would return which of the following?
Will disabling block caching improve scan performance?
You want to do a full table scan on your data. You decide to disable block caching to see if this
improves scan performance. Will disabling block caching improve scan performance?
where is the data saved first?
Your client application if; writing data to a Region. By default, where is the data saved first?
You need to free up disk space on your HBase cluster
You need to free up disk space on your HBase cluster. You delete all versions of your data that is
older than one week. You notice your delete has had minimal impact on your storage availability.
This is because:
Which additional feature does HBase provide to HDFS?
You have data already stored in HDFS and are considering using HBase. Which additional feature
does HBase provide to HDFS?
Given the following HBase table schema: Row Key, colFam_A:a, colFam_A:b, colFamB:2, colFam_B:10 A table scan w
Given the following HBase table schema:
Row Key, colFam_A:a, colFam_A:b, colFamB:2, colFam_B:10
A table scan will return the column data in which of the following sorted orders:
How many store files will be contained in your region(s) immediately following a major compaction?
Given the following dataset: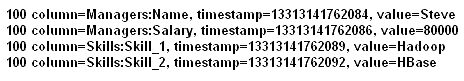
How many store files will be contained in your region(s) immediately following a major
compaction?
how many regions will your RegionServers have?
You have a total of three tables stored in HBase. Exchanging catalog regions, how many regions
will your RegionServers have?